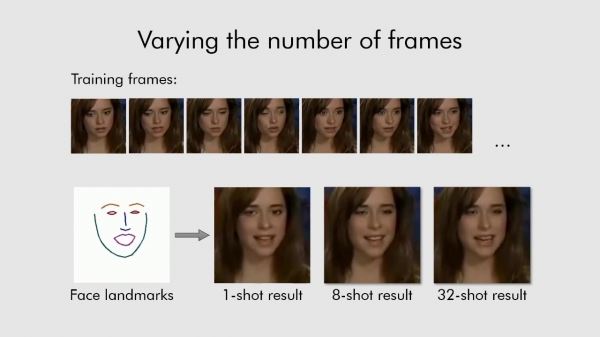
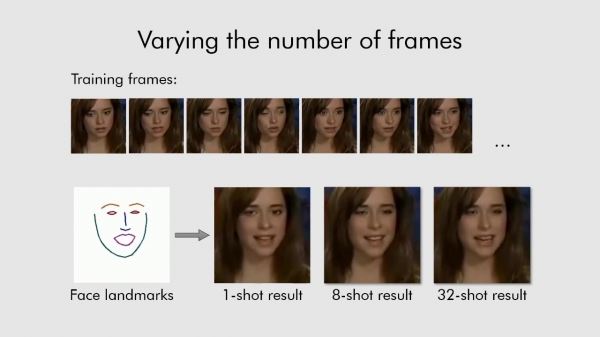
Российские специалисты из Центра искусственного интеллекта Samsung AI Center-Moscow в сотрудничестве с инженерами из Сколковского института науки и технологий разработали систему, способную создавать реалистичные анимированные изображения лиц людей на основе всего нескольких статичных кадров человека. Обычно в таком случае требуется использование больших баз данных изображений, однако в представленном разработчиками примере, систему обучили создавать анимированное изображение лица человека всего из восьми статичных кадров, а в некоторых случаях оказалось достаточно и одного. Более подробно о разработке сообщается в статье, опубликованной в онлайн-репозитории ArXiv.org.


Как правило, воспроизводить фотореалистичную персонализированную модуль лица человека довольно сложно из-за высокой фотометрической, геометрической и кинематической сложности воспроизведения человеческой головы. Объясняется это не только сложностью моделирования лица в целом (для этого существует большое количество подходов к моделированию), но также и сложностью моделирования определенных черт: полости рта, волос и так далее. Вторым усложняющим фактором является наша предрасположенность улавливать даже незначительные недоработки в готовой модели человеческих голов. Такая низкая толерантность к ошибкам моделирования объясняет нынешнюю распространенность нефотореалистичных аватаров, использующихся в телеконференциях.
По словам авторов, система, получившая название Fewshot learning, способна создать очень реалистичные модели говорящих голов людей и даже портретных картин. Алгоритмы производят синтез изображения головы одного и того же человека с линиями ориентира лица, взятых из другого фрагмента видео, или с использованием ориентиров лица другого человека. В качестве источника материала для обучения системы разработчики использовали обширную базу данных видеоизображений знаменитостей. Чтобы получить максимально точную «говорящую голову», системе необходимо использовать более 32 изображений.
Для создания более реалистичных анимированных изображений лиц разработчики использовали предыдущие наработки в генеративно-состязательном моделировании (GAN, где нейросеть додумывает детали изображения, фактически становясь художником), а также подход машинного мета-обучения, где каждый элемент системы обучен и предназначен для решения какой-то конкретной задачи.
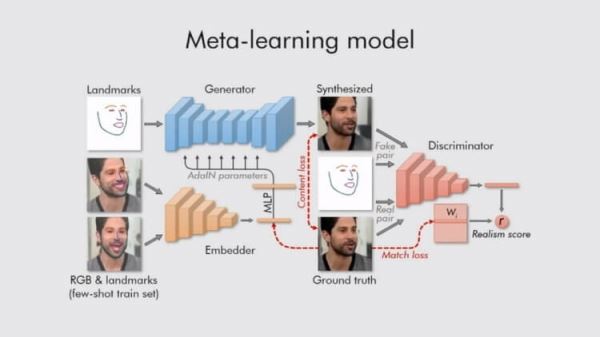
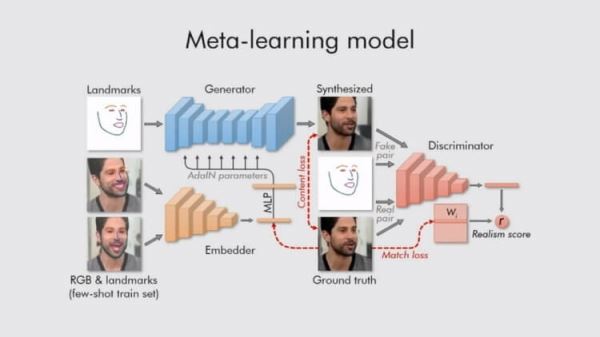
Схема мета-обучения
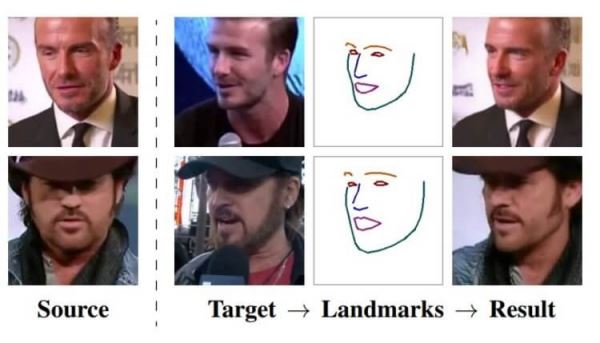
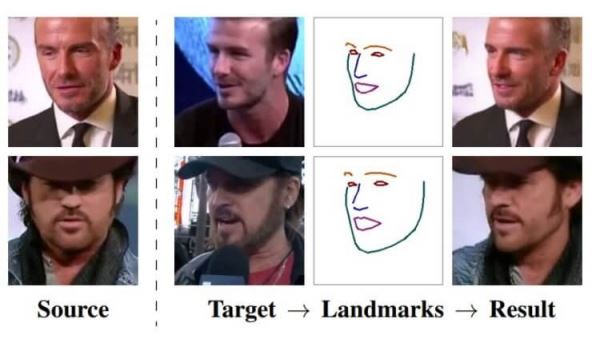
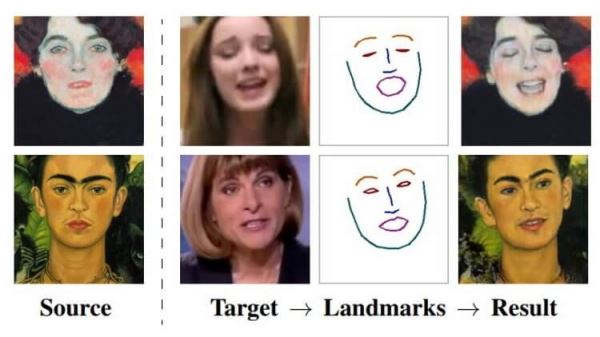
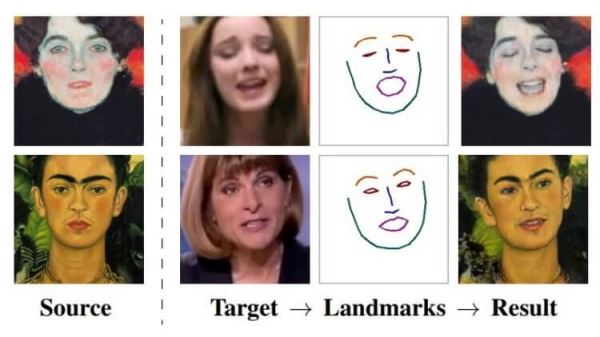
Для обработки статичных изображений голов людей и превращения их в анимированные использовались три нейросети: Embedder (сеть внедрения), Generator (сеть генерации) и Discriminator (сеть дискримитатор). Первая разделяет изображения головы (с примерными лицевыми ориентирами) на векторы внедрения, которые содержат независимую от позы информацию, вторая сеть использует полученные сетью внедрения ориентиры лица и генерирует на их основе новые данных через набор сверточных слоев, которые обеспечивают устойчивость к изменениям масштаба, смещениям, поворотам, смене ракурса и прочим искажениям исходного изображения лица. А сеть дискриминатор используется для оценки качества и подлинности работы двух других сетей. В результате система превращает ориентиры лица человека в реалистично выглядящие персонализированные фотографии.




Разработчики особо подчеркивают, что их система способна инициализировать параметры как сети генератора, так и сети дискриминатора индивидуально для каждого человека на снимке, поэтому процесс обучения может быть основан всего на нескольких изображениях, что повышает его скорость, несмотря необходимость подбора десятков миллионов параметров.